
저번 학기부터 Diffusion 분야를 처음 공부했다. 처음엔 너무 어려워서 무슨 소리인지 잘 몰랐는데, 계속 인터넷으로 공부하다 보니 내가 이해한건지 아니면 이해한다고 착각하는건지... 아무튼 나름대로 공부를 했다. 인터넷에 정말 방대한 소스가 있는데, 내가 공부할 때 가장 큰 도움이 되었던 블로그 4개를 기록해두었다. 솔직히, 다른 블로그 볼 필요 없이 아래 3개만 보면 된다. 특히, 1-2번째 블로그를 보며 속는셈 치고 모든 수식을 한 번만 따라해보았는데 큰 도움이 되었다.
내가 diffusion을 공부한 이후에 이해한게 맞는지 아리송할 때가 있었다. 그럴 때마다 DDPM의 forward process, backward process, loss function을 적어보고 classifier-free guidance 수식을 적어보았다. 이렇게 하면서 느낀 점 중에 중요한 것들을 간단히 정리했다.
1. DDPM은 VAE와 거의 동일하다.. 둘 다 gaussian distribution에서 reparameterization trick을 사용해 loss fuction을 표현하기 때문에 loss도 완전히 똑같다. 따라서 두 모델은 모두 ELBO를 사용해 loss function을 근사한다. 그럼 왜 diffusion이 VAE보다 압도적인 퍼포먼스이냐고? 그게 DDPM 모델의 묘미인 것 같다. diffusion은 가우시안 노이즈를 한 번씩 입히고, 다시 벗겨내는 과정이 있는데 DDPM 논문 기준으로 1000번의 노이즈를 입히고, 다시 벗겨낸다. 그럼 DDPM과 VAE의 차이점은 무엇일까?
- DDPM은 VAE와 다르게 encoder, decoder 구조가 없고 data dimension을 쭉 유지한다.
- DDPM은 encoder가 없다. VAE는 encoder가 neural network이지만, DDPM은 encoder가 neural network가 아니고 noise를 조금씩 뿌려가는 고정된 forward process이다. 그리고 이 forward process가 반드시 가우시안 distribution으로 수렴하게 된다.
- 또한 VAE는 각 layer마다 parameter가 sharing이 되지 않고 독립적이다. 하지만 DDPM은 reverse process에서 t가 condition 될 뿐, 하나의 모델이다.
- 그럼 DDPM이 VAE보다 성능이 훨씬 좋은 이유는 무엇일까?
- 만약 DDPM을 time step T만큼 가진 VAE라고 생각해보자. VAE는 encoder, decoder를 많이 쌓아봐도 몇십층에 불과하다. 하지만 DDPM은 1000개의 layer가 있는 decoder라고 생각할 수 있다. 또한 이때 모든 parameter는 sharing될 것이다.
- 여기서 생각할 수 있는 점은, VAE의 encoder가 encoding을 거의 안할 수도 있고, 할 수도 있다는 것이다. 이 모델이 어떻게 학습했는지에 따라 encoding 정도가 다를 수 있을 것이다. 하지만 DDPM은 fixed된 forward process가 schedule 된 대로 조금씩 noise를 더한다. 그리고 reverse process에서 그걸 되돌린다. 따라서 reverse process의 한 timestep이 매우 쉽다는 것이 보장된다. 항상 조금의 noise만 벗겨 내면 되기 때문이다. VAE는 encoder가 어떻게 했는지에 따라 decoder가 때로는 아예 없는 정보를 만들어야 할 수도 있고, 때로는 매우 쉬울 수도 있다.
- 정리하면 generation process라는 아주 어려운 과정을 1000개의 아주 작은 subtask로 쪼갠 것이 diffusion이다. 이때 하나의 subtask는 매우 쉽다. 마치 분할정복법 (devide and conquer)과 비슷하다. 그래서 DDPM이 VAE보다 압도적인 퍼포먼스를 보인다고 생각할 수 있다.
- VAE => 그냥 정해지지 않은 image generation task. encoder-decoder 구조이고, layer간 parameter는 sharing되지 않고 많아봐야 몇십개의 layer
- Diffusion => 가우시안 노이즈를 더하고 벗겨내는, 쉽고 보장된 task를 1000번 반복. 하나의 UNet에서 학습되며 모든 parameter는 sharing됨. encoder-decoder가 없고 data dimension을 유지함. 매우 어려운 image generation task를 noise라는 매우 쉬운 단계로 쪼개어 생각함.
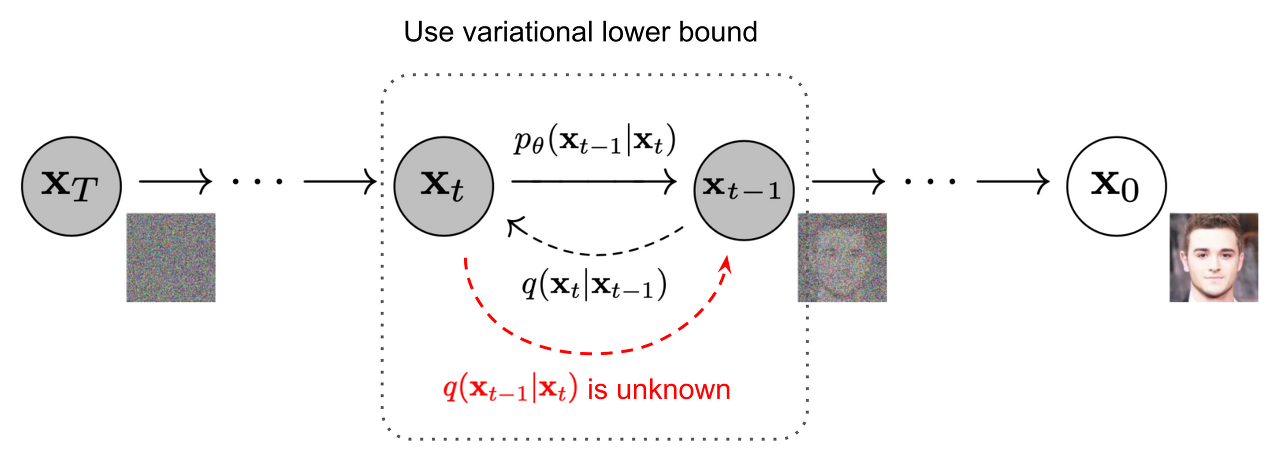
2. 조나단 호가 저자인 <Denoising Diffusion Probabilistic Models, 2020>논문은 사실 <Deep unsupervised learning using nonequilibrium thermodynamics, 2015> 논문에서 크게 바뀐 것이 없다. 하지만 이 원조 논문은 2015년에 나오고 묻혔는데.. 다시 이 방식을 꺼내서 적용했다는 것에 큰 의미가 있다. 이 논문의 contribution은 기존 2015년에 나온 논문에서 딱 하나의 term만 바꾼 데에 있다. 기존에는 가우시안 노이즈가 덮여진 이미지의 평균과 분산(분산은 여기서 고정시킨 함)을 학습하는 방식이었는데, 조나단 호가 수식을 조금 바꾸어 이미지가 아니라 노이즈만 L2 regression으로 학습하는 방식으로 바꾸었다. 그랬더니, 실제로 엄청 좋은 성능 향상이 있었다.
기존에는 forward process의 posterier의 mean을 regression 하는 문제였다면 (8), mean 항을 잘 정리해서 없애버리고 noise만 남긴 식(14)로 바꾸었다. 따라서 loss term이 바뀌었는데, 사실 우리가 맞춰야 하는 것은 noise 였던 것이다! 즉, 맞춰야 하는 범위를 더 좁힌 셈이다.
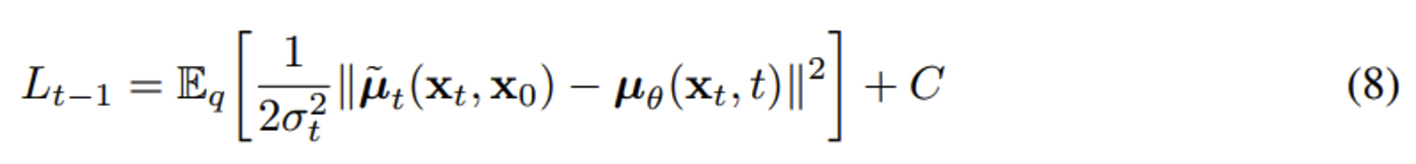
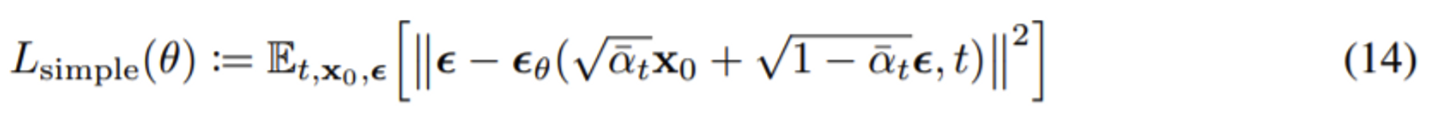
3. Score-based generative modeling
원래 score-based 방식은 score matching이라는 방식으로 다르게 발전되고 있었다. 어떤 data distribution을 모를 때, 그것에 대한 gradient를 어떻게 알고, 또 groundtruth로 어떻게 넣어 모델에 학습시킬 것인지에 대해 고민하던 중, 수학적으로 트릭을 써서 해결한 것이 2005년에 히바이엔이 발표한 score matching 방식이다. 쉽게 말해 expectation을 sample average로 근사하는 방식을 사용했다. 아무튼, diffusion과 score-based 방식은 서로 다르게 발전하고 있었지만 양송이 2021년 ICLR에서 diffusion과 score-based가 수학적으로 같음을 증명했다. DDPM같은 경우 general 한 SDE의 special한 case라고 볼 수 있다. 또한 양송이 쓴 논문에 있는 MSCN이라는 모델은 SDE의 다른 special case라고 생각할 수 있다.
Diffusion 기본 공부: 먼저 DDPM을 이해하자
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
⇒ 매우 유명한 post. 눈 한번만 감고 블로그에 있는 수식을 그대로 유도해보면 큰 도움이 된다.
https://www.notion.so/Diffusion-note-7a59284291d74221a301f5744c7d33f7
⇒ 김준호 님의 diffusion 노션 정리본. 정말 깔끔하게 정리되어 있다. 가끔씩 수식이 기억이 안나면, 이 블로그를 보면 바로 기억이 난다.
https://hyoseok-personality.tistory.com/entry/Concept-Diffusion-Models-with-DDPM-DDIM
⇒ 이 블로그도 개인적으로 매우 잘 정리되었다고 생각한다.
https://ivdevlog.tistory.com/14
⇒ 나쁘지 않은 블로그. 위 세개를 보고, 부족하면 이걸 보자.
그 다음 공부 순서
DDPM을 이해한 후에는 다음 순서로 공부하면 된다!
- DDPM (Ho et al, 2020)
- Improved DDPM (Nichol and Dhariwal, 2021)
- DDIM (Song et al, 2020)
- Score-based Generative Models
- Classifier Guidance
- Classifier-Free Guidance
- Latent Diffusion Models
위에 내용에 해당되는 논문 리스트는 아래와 같다.
- 아래 목록은 기본이 되는 diffusion 논문 리스트
[Sohl-Dickstein et al. 15] Deep Unsupervised Learning using Nonequilibrium Thermodynamics, ICML 2015.
[Song and Ermon 19] Generative Modeling by Estimating Gradients of the Data Distribution, NeurIPS 2019.
[Song and Ermon 20] Improved Techniques for Training Score-Based Generative Models, NeurIPS 2020.
[Ho et al. 20] Denoising Diffusion Probabilistic Models, NeurIPS 2020.
[Song et al. 21] Score-Based Generative Modeling through Stochastic Differential Equations, ICLR 2021.
[Nichol and Dhariwal 21] Improved Denoising Diffusion Probabilistic Models, ICML 2021.
[Vahdat et al. 21] Score-based Generative Modeling in Latent Space, NeurIPS 2021.
[Dhariwal and Nichol 21] Diffusion Models Beat GANs on Image Synthesis, NeureIPS 2021.
[De Bortoli et al. 22] Diffusion Schrodinger Bridge with Application to Score-Based Generative Modeling, NeurIPS 2021.
[Ho and Salimans 22] Classifier-Free Diffusion Guidance, arXiv preprint, 2022.
[Dockhorn et al. 22] Score-Based Generative Modeling with Critically-Damped Langevin Diffusion, ICLR 2022.
[Salimans and Ho 22] Progressive Distillation for Fast Sampling of Diffusion Models, ICLR 2022.
[Chen et al. 22] Likelihood Training of Schrodinger Bridge using Forward-Backwrad SDEs Theory, ICLR 2022.
- 아래 목록은 좀 더 발전된 diffusion 논문 리스트. 근데 위에 논문을 다 이해했다면 paper with code에서 관심있는 분야를 찾아보는것도 좋을 것 같다.
[Cohen et al. 22] Diffusion bridges vector quantized variational autoencoders, ICML 2022.
[Ho et al. 22] Video Diffusion Models, NeurIPS 2022.
[Chen et al. 23] Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions, ICLR 2023.
[Liu et al. 23] Learning Diffusion Bridges on Constrained Domains, ICLR 2023.
[Chung et al. 23] Diffusion Posterior Sampling for General Noisy Inverse Problems, ICLR 2023.
[Chen et al. 23] Seeing Beyond the Brain: Conditional Diffusion Model with Sparse Masked Modeling for Vision Decoding, CVPR 2023.
[Song et al. 23] Consistency Models, arXiv preprint 2023. => denoising을 one step으로 하는 논문
이렇게 기본적인 논문들을 읽은 후에는 자신이 원하는 논문을 마음것 읽자. 어떤 논문을 읽을지 고민된다면, 아래 깃허브 페이지를 참고하면 좋다.
이건 diffusion model들을 깃허브에 모아놓은 것이다.
https://github.com/diff-usion/Awesome-Diffusion-Models
GitHub - diff-usion/Awesome-Diffusion-Models: A collection of resources and papers on Diffusion Models
A collection of resources and papers on Diffusion Models - GitHub - diff-usion/Awesome-Diffusion-Models: A collection of resources and papers on Diffusion Models
github.com
이건 한국어로 한줄 정리되어 있는 깃허브 페이지. 작성자분께 정말 감사함을 전하고 싶다. 논문을 뭐읽을까 고민할 때 큰 도움이 되었다.
나도 논문을 읽고 이렇게 한줄로 정리해놓는 습관을 들여야 겠다.
https://github.com/kwonminki/One-sentence_Diffusion_summary
GitHub - kwonminki/One-sentence_Diffusion_summary: The repo for studying and sharing diffusion models.
The repo for studying and sharing diffusion models. - GitHub - kwonminki/One-sentence_Diffusion_summary: The repo for studying and sharing diffusion models.
github.com
'Paper > Diffusion' 카테고리의 다른 글
| A survey on Image Editing (1) | 2023.12.28 |
|---|
저번 학기부터 Diffusion 분야를 처음 공부했다. 처음엔 너무 어려워서 무슨 소리인지 잘 몰랐는데, 계속 인터넷으로 공부하다 보니 내가 이해한건지 아니면 이해한다고 착각하는건지... 아무튼 나름대로 공부를 했다. 인터넷에 정말 방대한 소스가 있는데, 내가 공부할 때 가장 큰 도움이 되었던 블로그 4개를 기록해두었다. 솔직히, 다른 블로그 볼 필요 없이 아래 3개만 보면 된다. 특히, 1-2번째 블로그를 보며 속는셈 치고 모든 수식을 한 번만 따라해보았는데 큰 도움이 되었다.
내가 diffusion을 공부한 이후에 이해한게 맞는지 아리송할 때가 있었다. 그럴 때마다 DDPM의 forward process, backward process, loss function을 적어보고 classifier-free guidance 수식을 적어보았다. 이렇게 하면서 느낀 점 중에 중요한 것들을 간단히 정리했다.
1. DDPM은 VAE와 거의 동일하다.. 둘 다 gaussian distribution에서 reparameterization trick을 사용해 loss fuction을 표현하기 때문에 loss도 완전히 똑같다. 따라서 두 모델은 모두 ELBO를 사용해 loss function을 근사한다. 그럼 왜 diffusion이 VAE보다 압도적인 퍼포먼스이냐고? 그게 DDPM 모델의 묘미인 것 같다. diffusion은 가우시안 노이즈를 한 번씩 입히고, 다시 벗겨내는 과정이 있는데 DDPM 논문 기준으로 1000번의 노이즈를 입히고, 다시 벗겨낸다. 그럼 DDPM과 VAE의 차이점은 무엇일까?
- DDPM은 VAE와 다르게 encoder, decoder 구조가 없고 data dimension을 쭉 유지한다.
- DDPM은 encoder가 없다. VAE는 encoder가 neural network이지만, DDPM은 encoder가 neural network가 아니고 noise를 조금씩 뿌려가는 고정된 forward process이다. 그리고 이 forward process가 반드시 가우시안 distribution으로 수렴하게 된다.
- 또한 VAE는 각 layer마다 parameter가 sharing이 되지 않고 독립적이다. 하지만 DDPM은 reverse process에서 t가 condition 될 뿐, 하나의 모델이다.
- 그럼 DDPM이 VAE보다 성능이 훨씬 좋은 이유는 무엇일까?
- 만약 DDPM을 time step T만큼 가진 VAE라고 생각해보자. VAE는 encoder, decoder를 많이 쌓아봐도 몇십층에 불과하다. 하지만 DDPM은 1000개의 layer가 있는 decoder라고 생각할 수 있다. 또한 이때 모든 parameter는 sharing될 것이다.
- 여기서 생각할 수 있는 점은, VAE의 encoder가 encoding을 거의 안할 수도 있고, 할 수도 있다는 것이다. 이 모델이 어떻게 학습했는지에 따라 encoding 정도가 다를 수 있을 것이다. 하지만 DDPM은 fixed된 forward process가 schedule 된 대로 조금씩 noise를 더한다. 그리고 reverse process에서 그걸 되돌린다. 따라서 reverse process의 한 timestep이 매우 쉽다는 것이 보장된다. 항상 조금의 noise만 벗겨 내면 되기 때문이다. VAE는 encoder가 어떻게 했는지에 따라 decoder가 때로는 아예 없는 정보를 만들어야 할 수도 있고, 때로는 매우 쉬울 수도 있다.
- 정리하면 generation process라는 아주 어려운 과정을 1000개의 아주 작은 subtask로 쪼갠 것이 diffusion이다. 이때 하나의 subtask는 매우 쉽다. 마치 분할정복법 (devide and conquer)과 비슷하다. 그래서 DDPM이 VAE보다 압도적인 퍼포먼스를 보인다고 생각할 수 있다.
- VAE => 그냥 정해지지 않은 image generation task. encoder-decoder 구조이고, layer간 parameter는 sharing되지 않고 많아봐야 몇십개의 layer
- Diffusion => 가우시안 노이즈를 더하고 벗겨내는, 쉽고 보장된 task를 1000번 반복. 하나의 UNet에서 학습되며 모든 parameter는 sharing됨. encoder-decoder가 없고 data dimension을 유지함. 매우 어려운 image generation task를 noise라는 매우 쉬운 단계로 쪼개어 생각함.
2. 조나단 호가 저자인 <Denoising Diffusion Probabilistic Models, 2020>논문은 사실 <Deep unsupervised learning using nonequilibrium thermodynamics, 2015> 논문에서 크게 바뀐 것이 없다. 하지만 이 원조 논문은 2015년에 나오고 묻혔는데.. 다시 이 방식을 꺼내서 적용했다는 것에 큰 의미가 있다. 이 논문의 contribution은 기존 2015년에 나온 논문에서 딱 하나의 term만 바꾼 데에 있다. 기존에는 가우시안 노이즈가 덮여진 이미지의 평균과 분산(분산은 여기서 고정시킨 함)을 학습하는 방식이었는데, 조나단 호가 수식을 조금 바꾸어 이미지가 아니라 노이즈만 L2 regression으로 학습하는 방식으로 바꾸었다. 그랬더니, 실제로 엄청 좋은 성능 향상이 있었다.
기존에는 forward process의 posterier의 mean을 regression 하는 문제였다면 (8), mean 항을 잘 정리해서 없애버리고 noise만 남긴 식(14)로 바꾸었다. 따라서 loss term이 바뀌었는데, 사실 우리가 맞춰야 하는 것은 noise 였던 것이다! 즉, 맞춰야 하는 범위를 더 좁힌 셈이다.
3. Score-based generative modeling
원래 score-based 방식은 score matching이라는 방식으로 다르게 발전되고 있었다. 어떤 data distribution을 모를 때, 그것에 대한 gradient를 어떻게 알고, 또 groundtruth로 어떻게 넣어 모델에 학습시킬 것인지에 대해 고민하던 중, 수학적으로 트릭을 써서 해결한 것이 2005년에 히바이엔이 발표한 score matching 방식이다. 쉽게 말해 expectation을 sample average로 근사하는 방식을 사용했다. 아무튼, diffusion과 score-based 방식은 서로 다르게 발전하고 있었지만 양송이 2021년 ICLR에서 diffusion과 score-based가 수학적으로 같음을 증명했다. DDPM같은 경우 general 한 SDE의 special한 case라고 볼 수 있다. 또한 양송이 쓴 논문에 있는 MSCN이라는 모델은 SDE의 다른 special case라고 생각할 수 있다.
Diffusion 기본 공부: 먼저 DDPM을 이해하자
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
⇒ 매우 유명한 post. 눈 한번만 감고 블로그에 있는 수식을 그대로 유도해보면 큰 도움이 된다.
https://www.notion.so/Diffusion-note-7a59284291d74221a301f5744c7d33f7
⇒ 김준호 님의 diffusion 노션 정리본. 정말 깔끔하게 정리되어 있다. 가끔씩 수식이 기억이 안나면, 이 블로그를 보면 바로 기억이 난다.
https://hyoseok-personality.tistory.com/entry/Concept-Diffusion-Models-with-DDPM-DDIM
⇒ 이 블로그도 개인적으로 매우 잘 정리되었다고 생각한다.
https://ivdevlog.tistory.com/14
⇒ 나쁘지 않은 블로그. 위 세개를 보고, 부족하면 이걸 보자.
그 다음 공부 순서
DDPM을 이해한 후에는 다음 순서로 공부하면 된다!
- DDPM (Ho et al, 2020)
- Improved DDPM (Nichol and Dhariwal, 2021)
- DDIM (Song et al, 2020)
- Score-based Generative Models
- Classifier Guidance
- Classifier-Free Guidance
- Latent Diffusion Models
위에 내용에 해당되는 논문 리스트는 아래와 같다.
- 아래 목록은 기본이 되는 diffusion 논문 리스트
[Sohl-Dickstein et al. 15] Deep Unsupervised Learning using Nonequilibrium Thermodynamics, ICML 2015.
[Song and Ermon 19] Generative Modeling by Estimating Gradients of the Data Distribution, NeurIPS 2019.
[Song and Ermon 20] Improved Techniques for Training Score-Based Generative Models, NeurIPS 2020.
[Ho et al. 20] Denoising Diffusion Probabilistic Models, NeurIPS 2020.
[Song et al. 21] Score-Based Generative Modeling through Stochastic Differential Equations, ICLR 2021.
[Nichol and Dhariwal 21] Improved Denoising Diffusion Probabilistic Models, ICML 2021.
[Vahdat et al. 21] Score-based Generative Modeling in Latent Space, NeurIPS 2021.
[Dhariwal and Nichol 21] Diffusion Models Beat GANs on Image Synthesis, NeureIPS 2021.
[De Bortoli et al. 22] Diffusion Schrodinger Bridge with Application to Score-Based Generative Modeling, NeurIPS 2021.
[Ho and Salimans 22] Classifier-Free Diffusion Guidance, arXiv preprint, 2022.
[Dockhorn et al. 22] Score-Based Generative Modeling with Critically-Damped Langevin Diffusion, ICLR 2022.
[Salimans and Ho 22] Progressive Distillation for Fast Sampling of Diffusion Models, ICLR 2022.
[Chen et al. 22] Likelihood Training of Schrodinger Bridge using Forward-Backwrad SDEs Theory, ICLR 2022.
- 아래 목록은 좀 더 발전된 diffusion 논문 리스트. 근데 위에 논문을 다 이해했다면 paper with code에서 관심있는 분야를 찾아보는것도 좋을 것 같다.
[Cohen et al. 22] Diffusion bridges vector quantized variational autoencoders, ICML 2022.
[Ho et al. 22] Video Diffusion Models, NeurIPS 2022.
[Chen et al. 23] Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions, ICLR 2023.
[Liu et al. 23] Learning Diffusion Bridges on Constrained Domains, ICLR 2023.
[Chung et al. 23] Diffusion Posterior Sampling for General Noisy Inverse Problems, ICLR 2023.
[Chen et al. 23] Seeing Beyond the Brain: Conditional Diffusion Model with Sparse Masked Modeling for Vision Decoding, CVPR 2023.
[Song et al. 23] Consistency Models, arXiv preprint 2023. => denoising을 one step으로 하는 논문
이렇게 기본적인 논문들을 읽은 후에는 자신이 원하는 논문을 마음것 읽자. 어떤 논문을 읽을지 고민된다면, 아래 깃허브 페이지를 참고하면 좋다.
이건 diffusion model들을 깃허브에 모아놓은 것이다.
https://github.com/diff-usion/Awesome-Diffusion-Models
GitHub - diff-usion/Awesome-Diffusion-Models: A collection of resources and papers on Diffusion Models
A collection of resources and papers on Diffusion Models - GitHub - diff-usion/Awesome-Diffusion-Models: A collection of resources and papers on Diffusion Models
github.com
이건 한국어로 한줄 정리되어 있는 깃허브 페이지. 작성자분께 정말 감사함을 전하고 싶다. 논문을 뭐읽을까 고민할 때 큰 도움이 되었다.
나도 논문을 읽고 이렇게 한줄로 정리해놓는 습관을 들여야 겠다.
https://github.com/kwonminki/One-sentence_Diffusion_summary
GitHub - kwonminki/One-sentence_Diffusion_summary: The repo for studying and sharing diffusion models.
The repo for studying and sharing diffusion models. - GitHub - kwonminki/One-sentence_Diffusion_summary: The repo for studying and sharing diffusion models.
github.com
'Paper > Diffusion' 카테고리의 다른 글
| A survey on Image Editing (1) | 2023.12.28 |
|---|