
최근에 VQA 논문에 대해 찾아보고 있었는데, VQA 분야가 발전된 흐름이나 최신 트렌드를 정리해놓은 글이 생각보다 적었다. 이것저것 조사하다 보니, 기록도 할겸 VQA 분야가 어떤 연구 트렌드로 변화했는지 정리해보았다. 그러고 보니 나는 Video Question Answering을 찾고 있었는데,, 일반적으로 부르는 VQA는 visual에 해당했다. 최근에는 video captioning, VQA, few-shot으로 Event prediction 까지 다양한 task를 다룰 수 있는 모델들이 나오고 있다.
VQA 분야란?
VQA는 말 그대로 "시각질의응답" 분야이다. Image와 Question을 동시에 입력받아서 Answer를 말하는 task이다. 아래 사진은 VQA를 검색하면 매우 많이 나오는 그림인데, 2015년에 나온 VQA 분야의 원조격 논문인 "VQA: Visual Question Answering"에 실려있는 이미지이다. 이처럼 질문을 던지면 답을 해주는 그런 AI model을 구축하면 된다. 이미지와 질문을 동시에 이해해야 하니, multimodal 을 얼마나 잘 활용하는지에 따라 성능이 결정된다.

그럼 초반에는 어떤 방식의 VQA 모델이 제안되었고, 현재는 어디까지 와있을까? VQA 분야가 어디까지 와있고, 어떤 방향으로 나아가는지 정리해보았다. 대략적인 흐름만 기록할 예정이다. 논문에 있는 자세한 experiment result 들은 생략했다.
VQA: Visual Question Answering (2015)
이 논문은 VQA 원조격에 해당하는 논문이다. 아래 그림이 전체 overview를 보여주고 있는 그림인데, image는 VGG 16을 사용해서 encoding하고 question은 LSTM encoder를 이용해 (1, 1024)의 vector를 추출해 두 vector를 point-wise multiplication 하는 방식의 간단한 네트워크를 사용했다.

- 초기 VQA : image는 CNN encoder, question은 LSTM encoder를 한 vector를 합치는 방식
- Pretrained VGG 16, LSTM 사용
- VQA task를 평가하는 accuracy 지표를 새롭게 사용했다. (기존의 ROUGE, BLEU metric 사용 안함..!)
- Answer의 종류로 open-ended 와 multiple-choice로 나눌 수 있다. open-ended는 아예 빈칸을 추론하는 것이고, multiple-choice는 여러 보기 중 하나를 선택하는 유형이다.
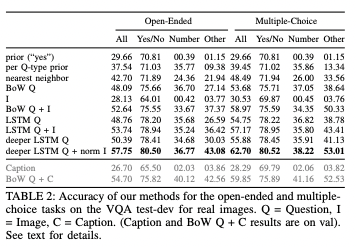
위 구조의 VQA 모델의 정확도는 위와 같다.
- Yes/No 중 하나만 답하면 되는 task는 accuracy 80.50
- Number를 답하면 되는 task는 accuracy 36.77..... (엄청 낮음)
Hierarchical Question-Image Co-Attention for Visual Question Answering (2016)
2016년부터는 seq2seq에서 효과적으로 bottleneck을 줄인 attention 기법이 여러 분야에 도입되기 시작했다. 참고로 "Attention is all you need" 논문은 2017년에 나왔고, 2016년이면 아직 transformer가 나오기 전이다. 따라서 VQA 모델에도 attention이 적용된 논문이 위 논문이다.


기존 VQA 구조와 비교하여 Image 쪽은 바뀐게 거의 없고, Question 부분 LSTM 구조가 Hierarchical하게 바뀐 것을 볼 수 있다. 여기서 Image와 Question 사이의 관계에서 더 semantic한 정보를 알아내기 위해서 Attention을 사용했다. Image와 Question을 attention해서 unified된 context vector를 추출했고, 이를 모델의 output으로 활용했다.
- Image와 Question 사이의 관계를 설명하기 위해 Attention 사용함
- Image feature 추출은 거의 변한게 없음
- Question에서 더 semantic한 정보를 뽑아니개 위해 LSTM 구조를 hierarchical 하게 변경
- Image와 Question을 attention -> unified context vector 추출
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering (2017)
이 논문의 아이디어는 매우 간단하다. 기존에는 전체 이미지를 Question과 attention하는데 사용했다면, 이젠 우리가 원하는 object만 추출한 일부 이미지 영역과 Question을 attention 하자는 아이디어다. 전체 이미지를 사용하는 방식을 Top-Down 방식, object detection 후 일부분만 사용하는 방식을 Bottom-Up 방식이라고 한다. 2017년부터 2020년까지는 이러한 Bottom-Up 방식의 VQA 모델들이 나오게 된다.

Bottom-Up 방식을 이용하면 한 Image에 대해 여러 개의 object 후보군이 생기는데, k개 만큼 생긴다고 하자. 아래 그림에서 Image features에 k*2048이라고 적혀있는 부분이 그것을 의미한다. 나머지 구조는 LSTM 대신 GRU를 사용한 것 이외에는 변하지 않았다.
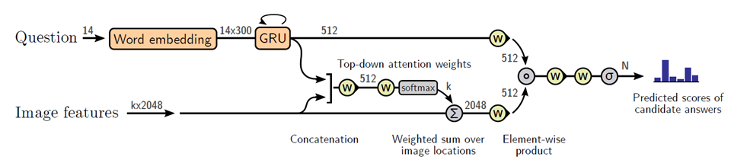
- 전체 이미지를 사용하는 Top-Down 방식은 Attention 범위가 너무 크다
- Object를 추출한 후 여러개의 Image feature와 Question을 attention하는 Bottom up 방법을 제안
- Bottom-Up 방법 중 Faster-RCNN을 사용함

위 결과가 매우 흥미롭다. Figure 7 위에는 기존 Top-Down 방식의 전체 이미지에 대한 attention이 적용되었을 때의 결과이다. A, man, sitting이 적힌 영역을 보면 매우 작다. 즉, 전체 이미지에서 모델이 "A"에 해당하는 부분은 저 조그만 pixel, "man"에 해당하는 부분도 저 조그만 pixel 영역으로 생각한다는 것이다. Semantic한 information을 잘 학습한게 아니라, 단어들에 대한 이미지 영역이 매우 좁은 pixel에 모여 있다.
반면 Bottom-Up으로 특정 이미지 영역을 정해주고, attention을 적용하면 훨씬 semantic하게 잘 학습됨을 알 수 있다. "A"와 "man"에 해당하는 면적이 꽤나 넓어졌고 의미적으로도 유사하다.
현재: 언어모델의 supervision을 이용한 VQA 네트워크 (2020 ~ now)
그렇다면 현재 VQA 모델은 어떤 방식으로 제안되고 있을까? 최근에는 언어모델(GPT-3, BERT)의 엄청난 퍼포먼스로 인해 언어모델의 supervision을 이용한 연구가 활발히 진행되고 있다. 언어모델이 아니더라도 language-vision 에 대해 contrastive learning으로 매우 좋은 성능을 보인 CLIP도 자주 사용된다. 대표적으로 Flamingo가 있으며, Socratic Model 계열, prompting tuning 방식 등이 있다.
Flamingo: a Visual Language Modelfor Few-Shot Learning (2022)
Flamingo는 few-shot으로 몇 가지 example만 보여주면 그에 따른 답을 만들어주는 모델이다. VQA 뿐만 아니라 chat-bot 기능, Image captioning 등 다양한 분야에 사용될 수 있다. 여기서 few-shot으로 example을 준다는 뜻은 다음과 같다.

위 그림은 3-shot을 주었을 때의 결과를 의미한다. 즉, 3개의 example을 보여주고 "자 이제 너가 다음 올 문장을 완성시켜봐!"라고 외치는 것이다. 신기하게도 이미지-text 순서에 따라 유동적으로 다양한 task를 수행할 수 있다. 맨 밑에 숫자의 덧셈도 할 수 있다.
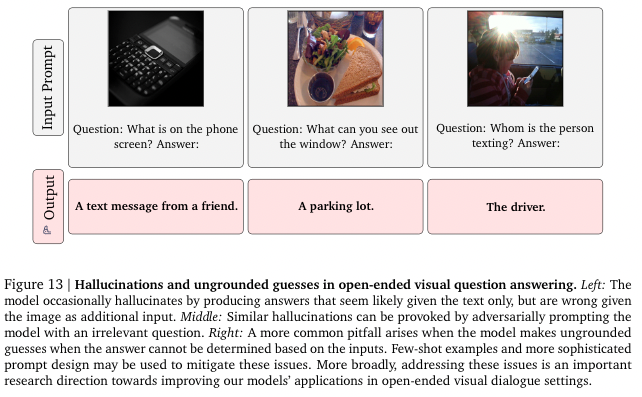
Flamingo는 prompt에 이미지-text pair로 이미지와 Question을 주면 VQA 에 대해서 잘 수행할 수 있다. Flamingo는 실제로 몇 개의 VQA 데이터셋에 대해 SOTA를 차지했다. 그럼 Flamingo의 모델은 어떤 구조로 되어있을까?
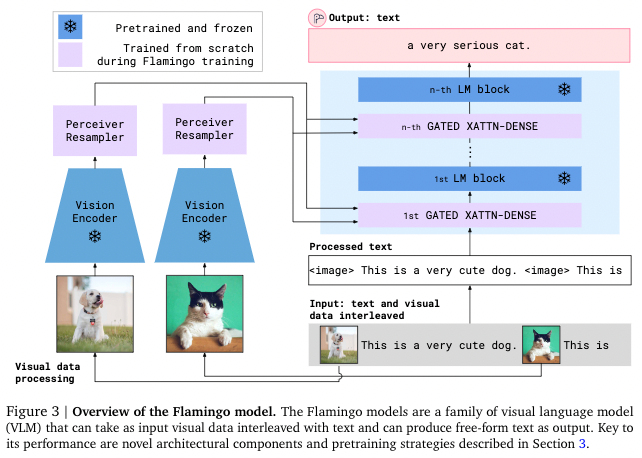
Flamingo 모델은 CLIP 모델의 vision encoder(ViT), text encoder를 frozen하여 그대로 사용했다. Image-text pair를 서로 attention하여 학습하기 위해 다음 2가지의 새로운 구조를 도입했다.
- Perceiver Resampler
Vision encoder로 얻은 feature들을 고정된 작은 사이즈의 visual token으로 mapping하는 역할을 한다. Visual token의 출력 size가 작을수록 vision-text cross attention의 계산량을 줄일 수 있어, 긴 비디오를 처리할 때 매우 유용하게 사용된다.
(Bottom-Up 구조로 attention 계산량을 줄이는 아이디어는 동일하다!)
- Gated Cross Attention layers
Visual token과 text를 attention하는 layer이다. 이때 Attention의 key, value 값은 vision feature에서 얻고, query를 language feature에서 얻는다. 따라서 이 layer에서는 vision과 language 정보를 통합해 LM block이 다음 token을 예측하는 task를 수행하는데 도움을 준다.
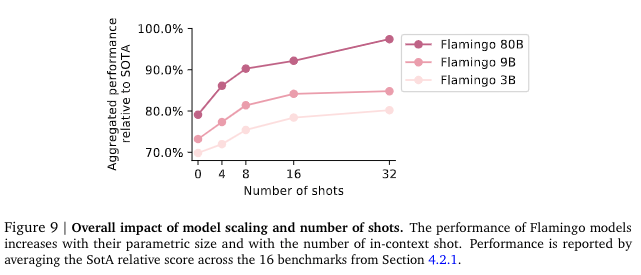
Flaming는 parametric size가 클수록 성능이 좋아지고, in-context shot (위에서 언급했던 few-shot의 개수!) 숫자가 증가할수록 성능이 좋아졌다. 사실 parameter size가 증가한다고 무작정 모델 정확도가 좋아지기 어렵다. 하지만 Flamingo는 CLIP을 frozen하고 몇 가지 layer만 추가한 모델이기에 CLIP과 유사하게 parametric size가 클수록 좋은 성능을 보이는 경향을 보이고 있다.
정리
VQA 분야는 image와 question 사이의 semantic 정보를 얼마나 잘 얻어내는지가 중요한 분야이다. 기존에는 image와 question 사이의 attention을 사용한 기법이 사용되었지만, CLIP 모델이나 GPT-3 등 language supervision을 사용한 모델들이 최근에 나오고 있다. Flamingo는 CLIP을 개량한 모델이며, Socratic Model은 CLIP + GPT-3 로 만든 모델이다. 따라서 초거대 언어모델의 성능을 VQA 분야에 끌여들여 기존의 낮은 BLEU score를 올리려는 노력들이 증가되고 있지만, 다른 vision 분야에 비해 조용한 것은 사실이다.
Visual Question Answering 분야는 아직 accuracy가 높은편이 아니기에 challenge한 분야인 것 같다. 최근 몇 년 동안 multimodal learning이 트렌드로 자리잡으면서 자연스럽게 VQA에도 언어모델을 사용하는 경향이 있지만, 아직 발전가능성이 많은 분야이다. 더 나아가 Video Question Answering 분야도 매우 재미있을 것 같다. Video야말로 아직 발전할 것이 많은 분야인 것 같다.
남들이 많이 하는 vision task를 할지, 아니면 VQA와 같은 유명하진 않지만 아직 발전가능성이 높은 분야를 할지 전략적으로 잘 선택해서 연구를 진행해야 겠다는 생각을 했다.
'Paper > Multimodal Learning' 카테고리의 다른 글
| [논문] CLIP : Learning transferable visual models from natural language supervision (3) | 2022.08.08 |
|---|